Introducing
 Fast, Intelligent Automation Co-Pilot for Seamless QA — Explore Now!
Fast, Intelligent Automation Co-Pilot for Seamless QA — Explore Now!
Fast, Intelligent Automation Co-Pilot for Seamless QA — Explore Now!
An efficient approach to quickly identify and correct problematic data
CloudBerry360's innovative automated data observability framework in the cloud assists data platform teams and engineers in quickly identifying issues with Spark and Databricks jobs throughout their data pipelines. It enables faster remediation of failed and long-running jobs and proactive optimization of overprovisioned compute resources to cut costs. Distinguishing itself from traditional infrastructure monitoring tools, native interfaces, and log analysis, our automated toolkit is the only solution that allows teams to delve into job execution traces at the Spark stage and task level. This unique capability makes it easier to resolve issues and seamlessly correlate job telemetry with cloud infrastructure—within the context of the entire data stack.
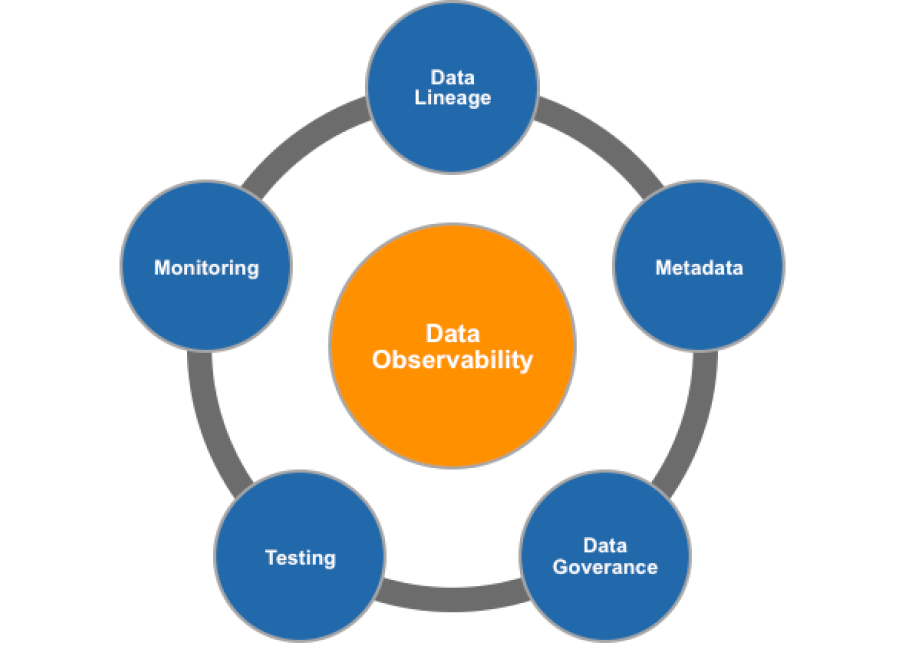

By implementing Data Ops and observability, you significantly decrease the likelihood & duration of data-related disruptions, ensuring your operations remain smooth and efficient.

These practices streamline your data management processes, reducing the time spent on detecting and resolving data issues, thus freeing up resources for other critical activities.

With enhanced monitoring & proactive maintenance, you can substantially improve the breadth & depth of your data quality checks, ensuring higher data integrity.

Automation tools analyze potential impacts of data issues, allowing your team to focus on high-priority areas & strategic initiatives rather than routine checks.

Data Ops & observability systems provide timely, actionable alerts directly to appropriate teams, enabling quicker responses to potential issues before they escalate.

Easily track incident tickets, monitor their severity, & check their status to manage data issues more effectively & maintain accountability within your teams.

Keep stakeholders informed with real-time displays of data product service level agreements (SLAs) and health statuses, ensuring transparency & ongoing compliance with performance standards.
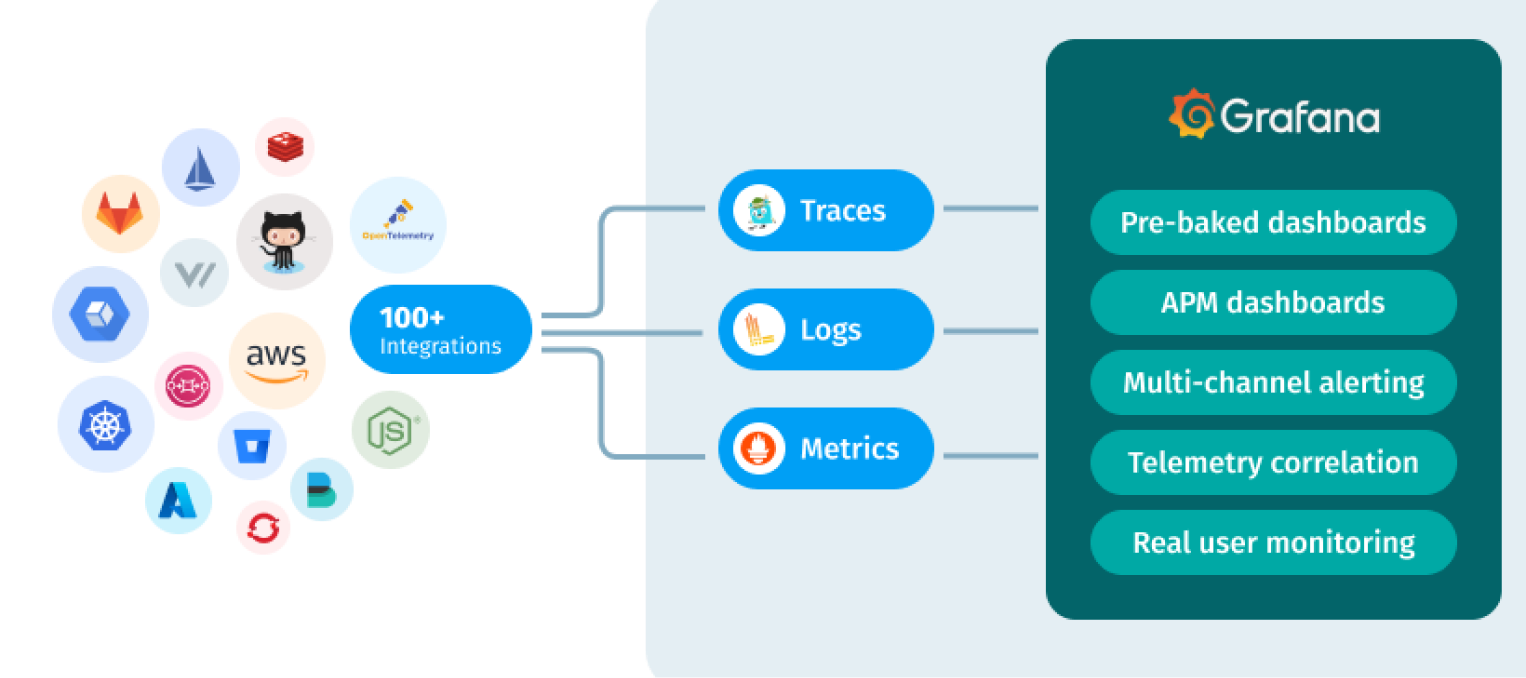

We aim to be a leading innovator in designing, building and supporting critical business management solutions on cloud platforms that will help transform your organization and align with your business goals
Quick links
Services
Contact info
